Ho:µ=15
Ha:µ not equal to 15
A sample of 50 provided a sample mean of 14.15. The population standard deviation is 3.
a. compute the value of the test statistic.
b.What is the p-value.
c. At a=.05 what is your conclusion?
d. what is the rejection rule using the critical value? what is your conclusion?
Worked solution:
We’re asked to calculate a test statistic. Note carefully that I am going to use the t distribution below----theoretically the normal distribution would work because n > 30, but I am super-careful and always use the t distribution for this.
Recall that we get the test statistic from

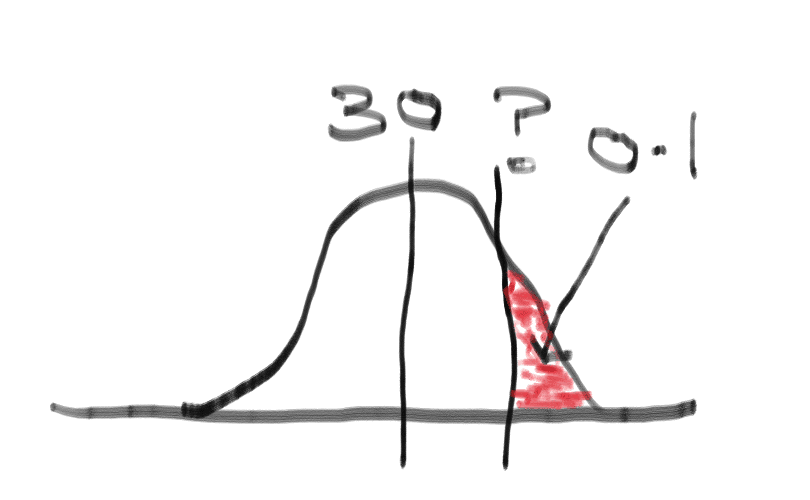
So now use Excel: =tdist(2.005,49,2)= 0.0505
degrees of freedom is n-1 = 50 -1 =49
tails is 2 ----look at the hypothesis
The p value is 0.0505. We are asked to test at 95% (meaning alpha = 0.05), so here p NOT smaller than or equal to alpha because 0.0505 > 0.05. Conclusion is fail to reject null hypothesis.
Note: this is very borderline case. A bit of rounding off the other way.....might have been a different conclusion.
The last part of the question asks about using the critical value. In my class I teach you ONLY the p value, so don’t worry about this part of the question.